The 4.5 Kinds of DevTool Platforms
How to make sense of the overwhelming world of Developer Tooling
One of the most immediate problems I encountered when starting to work and invest in devtool startups was my lack of a good mental model for assessing them.
I think I have finally found one, and I call it The 4.5 Kinds of Devtool Platforms:
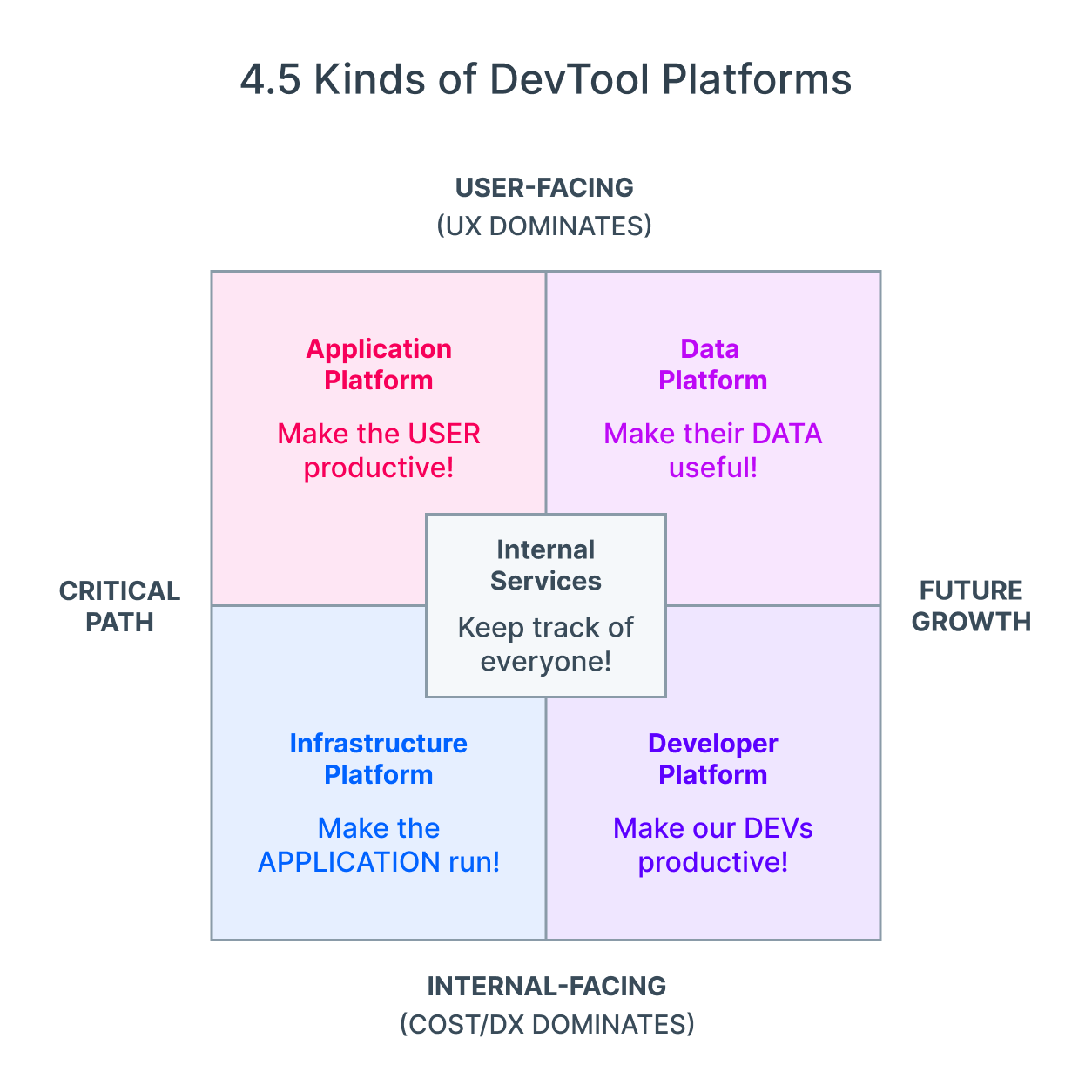
image credit: @arthurwuhoo!
Context
If you listen to their marketing, every startup is destined to destroy the legacy way of doing things. Every startup has no competent competitors. Every startup is in the top right of their 2x2. Every startup is going to grow to the moon.
But:
- To have a decent exit, a startup will need a path toward $100m ARR in 5-10 years.
- Individually, you could always make a case that exceptional founders will figure it out.
- Collectively, it is madness to expect that all of them will.
Whether you are thinking about joining a startup or investing in one, the problem is the same - having to turn from a positive-sum "Everyone can win! You're doing great honey!" mindset to a zero-sum mindset. Not because you actually believe there can only be one winner, but because there is only a finite amount of your time and money to invest.
One way to decide is by going top-down instead of bottom-up. As @pmarca often notes - "When a great team meets a lousy market, market wins. When a lousy team meets a great market, market wins." Follow the money, and you can start to impute some hard market sizing numbers on the fuzzy language.
Yet the available models have not really clicked with me. Greylock's Jerry Chen notes 32 distinct investment categories of Castles in the Cloud. Dell's Tyler Jewell made a Developer-Led Landscape chart with 4 groupings of 23 subcategories, and yet no mention of security or networking. (These two are the biggest I can remember, please let me know if I have missed well known devtool landscapes/breakdowns). The numbers of categories don't bother me so much as the fact that they are retroactive backfits. From my time as a hedge fund analyst I know how uncomfortable I felt without a good mental model of my coverage universe, and this is no different.
In our attempt to follow the money, we risk forgetting that money follows tech, not the other way around. When we are investing, we get paid for being nonconsensus and right, and that means identifying new or growing or shifting markets from first principles can have incredible rewards.
The ideal mental model of devtools should be:
- defensible from first principles
- roughly proportional to the amount of money spent in a tech startup
- easy to remember
After a few years of thinking and searching, I think I have found a top-down model that works. It isn't complete by any means (it lacks a full TAM analysis for each segment), but I think there is enough that I feel I have gained useful insight to share.
The SDLC Approach
One way to sort devtools in a top-down manner is to ask yourself which part of the Software Development LifeCycle (SDLC) the tool corresponds to. Beyang of Sourcegraph breaks it down as such:
- Plan and describe what the software should do
- Read and understand the code being modified
- Write, run, and debug the new code
- Test the code
- Review the code
- Deploy the code
- Monitor the code in production and react to incidents
Aside: Some people take issue with the linear SDLC model, so Emily Freeman at AWS has been promoting an alternative model with 6 circles and 6 axes. Full intro video here, but it is too early to tell if this framing will stick.
This is sufficiently general that it is language agnostic, but detailed enough that you can probably pick your favorite ecosystem (or whatever you use at work) and map specific names of tools and companies to one or more of these stages. With this understanding, for example, we can see that the category of tools covered in the End of Localhost would range from stage 3-6 or even 2-6.
If your company is lucky enough to have an internal developer productivity/infrastructure/experience team, you might even see internal tools that you use to meet those needs. Netflix has a nice simplification of the SDLC into an easier-to-remember three tiers (citation, source):
- Zero to Dev: e.g. Newt, their bootstrapping system
- Dev to Prod: e.g. Spinnaker, their CI/CD system
- Prod to Dev: e.g. Atlas, their Telemetry platform
Another well loved decomposition of the SDLC is the Accelerate/DORA metrics:
- Deployment Frequency: Refers to the frequency of successful software releases to production.
- Lead Time for Changes: Captures the time between a code change commit and its deployable state.
- Mean Time to Recovery: Measures the time between an interruption due to deployment or system failure and full recovery.
- Change Failure Rate: Indicates how often a team’s changes or hotfixes lead to failures after the code has been deployed.
While the DORA group was focused on the developer Outer Loop (definition here), you can still usefully repurpose these ideas to try to understand what process or tooling improvements you can make for the software delivery metrics that are underperforming.
Regardless of what SDLC model you adopt, once you understand the gaps in tooling, you can understand the potential of whatever startup you are considering. You can try to quantify time spent on each in terms of engineer-hours spent, assume some % that could be saved with the tool, and somewhat justify what % of that value created will be captured by the company selling the tool and therefore what it could be worth.
The SDLC approach was the primary way I understood developer tools until I notice the sheer number of developer-oriented startups that did not fit neatly into this model.
Most noticeably, Infra startups.
The Infra Approach
My first disillusion with the SDLC framing of developer tools came from talking with enough open source software startups and noticing a common pattern:
- All of them start out with some promising improvement in the SDLC
- They get great OSS adoption and take funding to build a cloud service (because licensing and support are SO 20th century)
- The cloud service starts charging on metrics that are basically disconnected with the SDLC improvement - because SDLC is hard/very invasive to quantify
Ultimately, the First Principle of Technology is that everything can be broken down into some combination of compute, storage, and networking, and that is what most devtool startups end up charging for anyway:
- It closely matches underlying expenses
- Customers understand that they should pay for these things - it loosely matches a networked version of von Neumann architecture
- Most startups move from seat-based to usage-based billing in order to promote usage and natural expansion revenue
So shouldn't you really be breaking down tools based on the source of money they are making instead of the random fuzzy unmeasurable multicausal SDLC story they happen to be hawking?
The best perspective on this I have found from David McJannet, CEO of Hashicorp (podcast, chart source):

Here are the "tiers" of chargable infrastructure I have gathered so far:
- Datacenters: Space, Power, Connectivity (Interconnects)
- Base components: CPU, Storage, Bandwidth
- Infra platform: Infra, Security, Networking*
- App platform: Runtime, Message Queue, Database
- Monitoring: APM/Observability tools
note that Networking probably splits into internal* - between services, inside a VPC - and external, customer facing or egress-type charges - this makes it rather annoying to visualize neatly in a stack diagram so I have simply not bothered with one.
Notice that this "infra-centric" view of the world omits productivity/collaboration tools like GitHub or Jetbrains or Atlassian/Jira, so we have clearly lost generality from the SDLC view of the world.
But wait - Is Infrastructure a "DevTool"? Arguably we are playing fast and loose with the definition of "devtools" already - most other authors I cite in the previous section are clearly thinking of application developers, whereas I am adopting a more expansive view of how much infra is owned and managed (or at least designed for) by developers. Aren't "Infra as Code" and "Serverless" and other modern movements successfully blurring the distinction?
Still, I like this model better than the SDLC one because it probably leads to a better understanding of how money is made: I strongly suspect that the median successful Devinfra startup is more valuable than the median successful Devproductivity startup (citation needed!). From a certain point of view, Devinfra is the "B2B" version of devtools while Devproductivity is "B2C".
Aside: this analogy makes sense from a "go to market" perspective as well - Devproductivity is much more "product led", bottom-up growth, while Devinfra tends to be a top-down, longer buying cycle.
We can even try to integrate the SDLC and the Infra centric view of the world with some support for Low/No Code end-user application development. In the Coding Career Handbook I sketched out a "stack" of these layers, inspired by the OSI model:
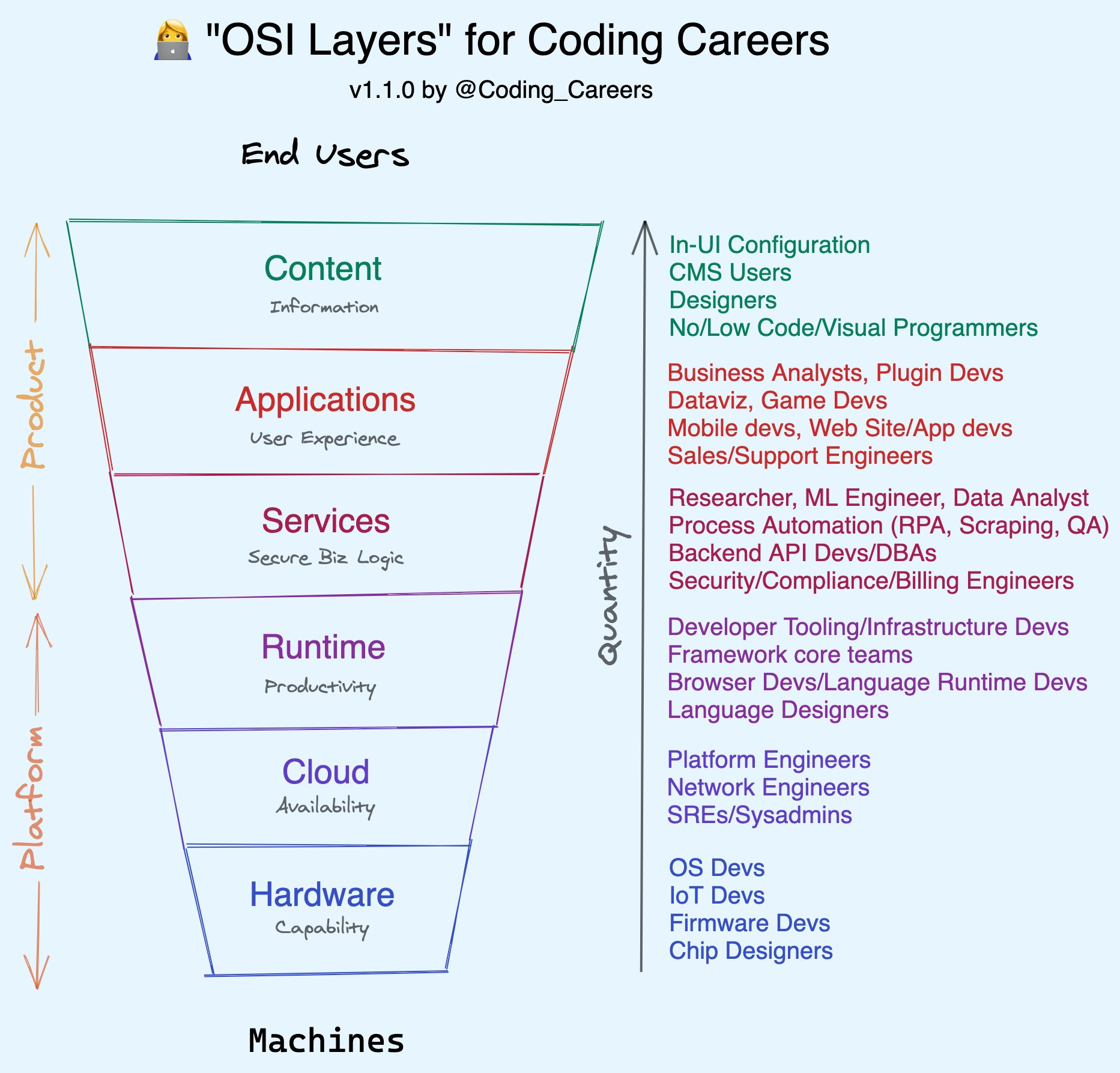
This seems like a vaguely workable decomposition of the world. And yet, it is still inadequate.
We've underestimated the role of data.
The Data-centric Approach: Money follows Data
While storage is a commodity and it trends ever cheaper, there's a certain gravity to data that ties money wherever it goes. From a first principles point of view, if your startup went from running to not running - had data flowing in and out and then suddenly paused - your compute and networking costs would go to 0, but you'd still be charged for data at rest.
The amount to which I believe that "money follows data" cannot be understated. In my first meeting with Sarah Catanzaro, I remember blurting out my secret belief that "almost all successful companies are really data companies" (if you also include database, data pipeline, and/or data model). I even jokingly expanded it into Zawinswyx's Law:
Every startup attempts to expand until it runs a custom database. Those startups which cannot so expand are replaced by ones which can.
Some examples:
- Some Notion engineers I've spoken to consider themselves to be really running a custom database that happens to have a nice UI
- Honeycomb spent 2 years writing a columnar, high cardinality "not-a-database"
- Datadog is basically a few hundred "domain specific databases" (announcement, case study)
- Expensify runs "a private Blockchain-based data foundation atop a custom fork of SQLite"
- Jira and Asana are successful data models for storing tasks
- Zendesk and Front are successful data models for customer support
- Twitter and Reddit are successful data models for storing text content
- Orbit and CommonRoom are data pipelines for community data
- etc...
Trivially, this is not much bolder of an observation than the fact that every successful startup vies to be a system of record for something (and the fact that the average startup now has ~100 SaaS services all trying to be data silos for your data has led me to be interested in long tail ELT - #plug). But of course, instead of building your own database, you could buy it...
We're getting a little sidetracked. There are two loosely related halves of note in the data world:
- Operational Data: older databases like MySQL and Postgres (from the small hosts like Supabase to the large ones like RDS and Aurora), and newer databases like MongoDB (18b) and CockroachDB (5b) and Planetscale and Yugabyte and SingleStore and Neon and 10 other variants of scalable NewSQL database companies.
- Analytical Data: I'll just state the obvious that Snowflake (46b) and Databricks (38b) have been one of the biggest startup successes of the past decade, and that's even without specific numbers for Redshift and BigQuery and Synapse. Nor are we considering the BI universe of Tableau (15b), Qlik (3b), Looker (2.6b), Domo, Alteryx, and more.
Operational Data matters a lot for developers making applications, whereas Analytical Data matters more for business analysts, PMs, and data scientists gaining insights. This is a loose distinction, because of course the highest form of "data-led" user experience feeds right back into the application itself (e.g. Tiktok)
Aside: But databases aren't "data"??
To be clear, when most people talk about "data engineering" and "big data" they usually mean just analytical data, and that is what I have reflected in my diagram at the end. Data warehouses and pipelines and BI are a big enough category of their own. "Operational" databases tend to be slotted into application or infrastructure categories. However I do think that the distinction isn't as clear cut as may seem and we often try to "operationalize" the analytical data.
Throw a rock and you'll hit a current or future unicorn in the data world. The opportunity in data alone is demonstrably much bigger than the proportionately tiny space given to it in the Hashicorp diagram, because the Infra view of the world gives equal emphasis to each infra component. But they are not made equal. Data is special. Give it the attention it deserves.
There's the gatekeeping question again - is "data tooling" really "devtools"? A business analyst building dashboards or slinging SQL, or a data scientist running Tensorflow or PyTorch, wouldn't really consider themselves developers as their primary identity. But more and more of dev workflow and tooling is eating this world too.
The most useful data landscape probably comes from Martin Casado's team at a16z:
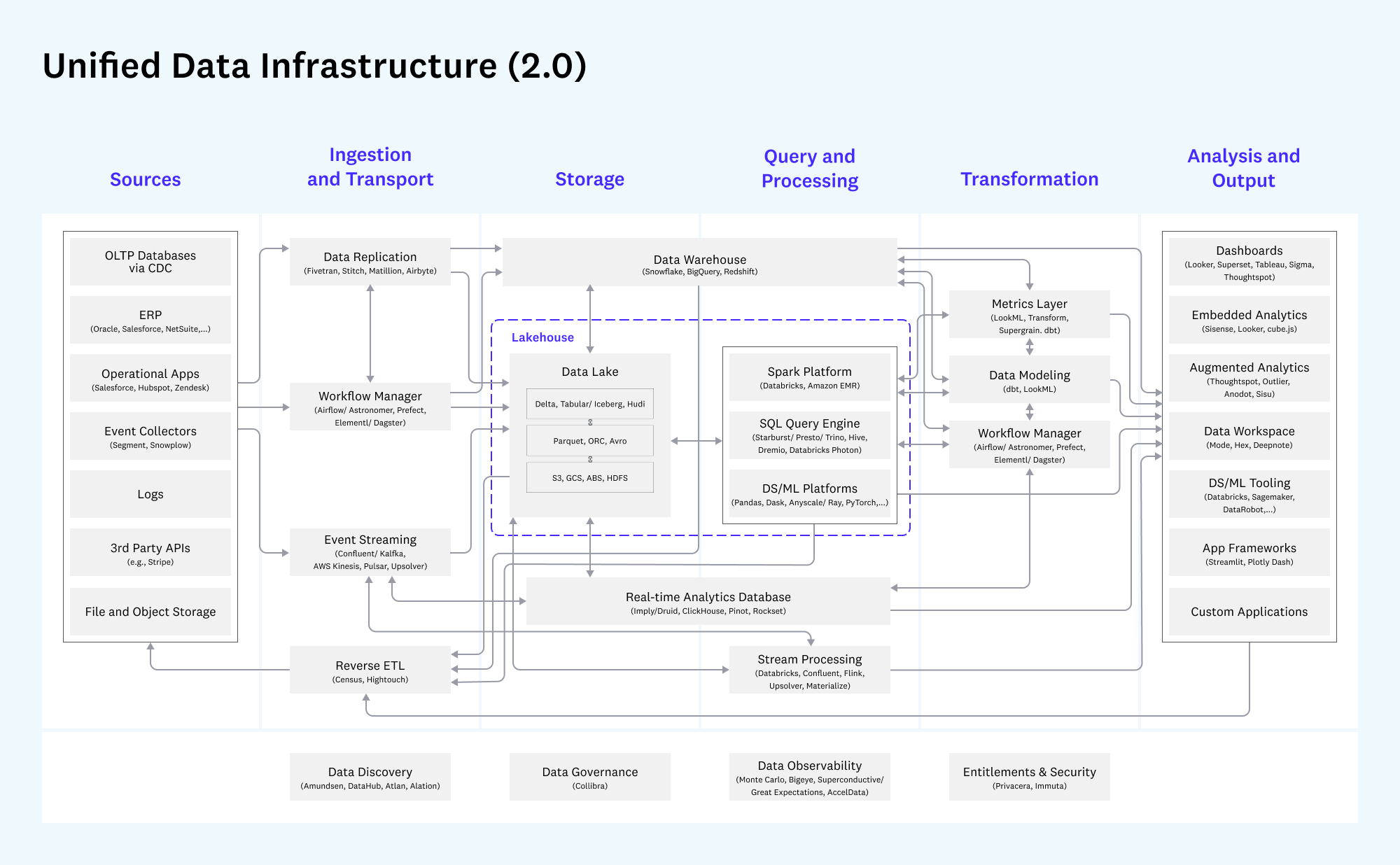
The Internal Platform of Platforms
There are further imperfections to the neatly divided Infra-centric Hashicorp/McJannet model. At least two disciplines cut across all segments: monitoring and security.
Notice that the APM function (mostly owned by Datadog (32b), but Dynatrace (12b), New Relic (4b), and Sentry (3b) are in the mix) is drawn as cutting across all parts of the application and infra platform. If you broaden out monitoring to include observability then you may throw in Honeycomb and Lightstep as important players in the space.
If you talk to any security folks, they'll also seem wonderfully cross-cutting. Jack Naglieri of Panther breaks a typical security setup into:
- application security (authn/authz of product - eg interaction of customers with rails app)
- data security (access to production data - encryption, access logs, auditing)
- infrastructure security (collecting telemetry, understanding state of infra & activity within)
- incident response team (containment, forensics, reporting, controls)
- security compliance team (compliance checks)
So essentially, there is a matching security and monitoring role for every part of the devtools stack that we have already identified, with a little extra for maintenance/response.
You might imagine other centralized services belonging in this bucket. One of the reasons it was surprisingly hard to pitch Temporal was that while workflow engines are often viewed as operational/hot path tools (and this drove more infra usage), a lot of the initial usecases were more infrequent, ranging from database migrations to infrastructure provisioning. So there would be a wide range of usecases across application, infra, and data, but the central workflow engine team (like Stripe's) would keep all of them running to provide everyone else a clean abstraction of durable long-running compute+state.
You can see Armon Dadgar sum up Hashicorp's experience of why companies build platform-of-platforms as solving for (in phase 2 of cloud adoption) reusable patterns (workflows?), security/compliance, leverage, and (in phase 3 of cloud adoption) multicloud, private cloud, and automation for self serve.
The road to the internal "Platform of Platforms" is one paved with good intentions but riddled with potholes of premature optimization. When you have a situation of every vendor trying to sell you (or worse, engineers trying to build internally) a "single pane of glass" to give visibility across all the things, you might just end up with a glasshouse.

The 4.5 Kinds of Platforms
With thanks to all the previous inspirations, we can put all our insights together into one model:
image credit: @arthurwuhoo!
I have intentionally avoided attaching specific logos to each category in an attempt to avoid getting bogged down in debating specifics (where I have more room for mistakes), but we went ahead and put some up in case it helps: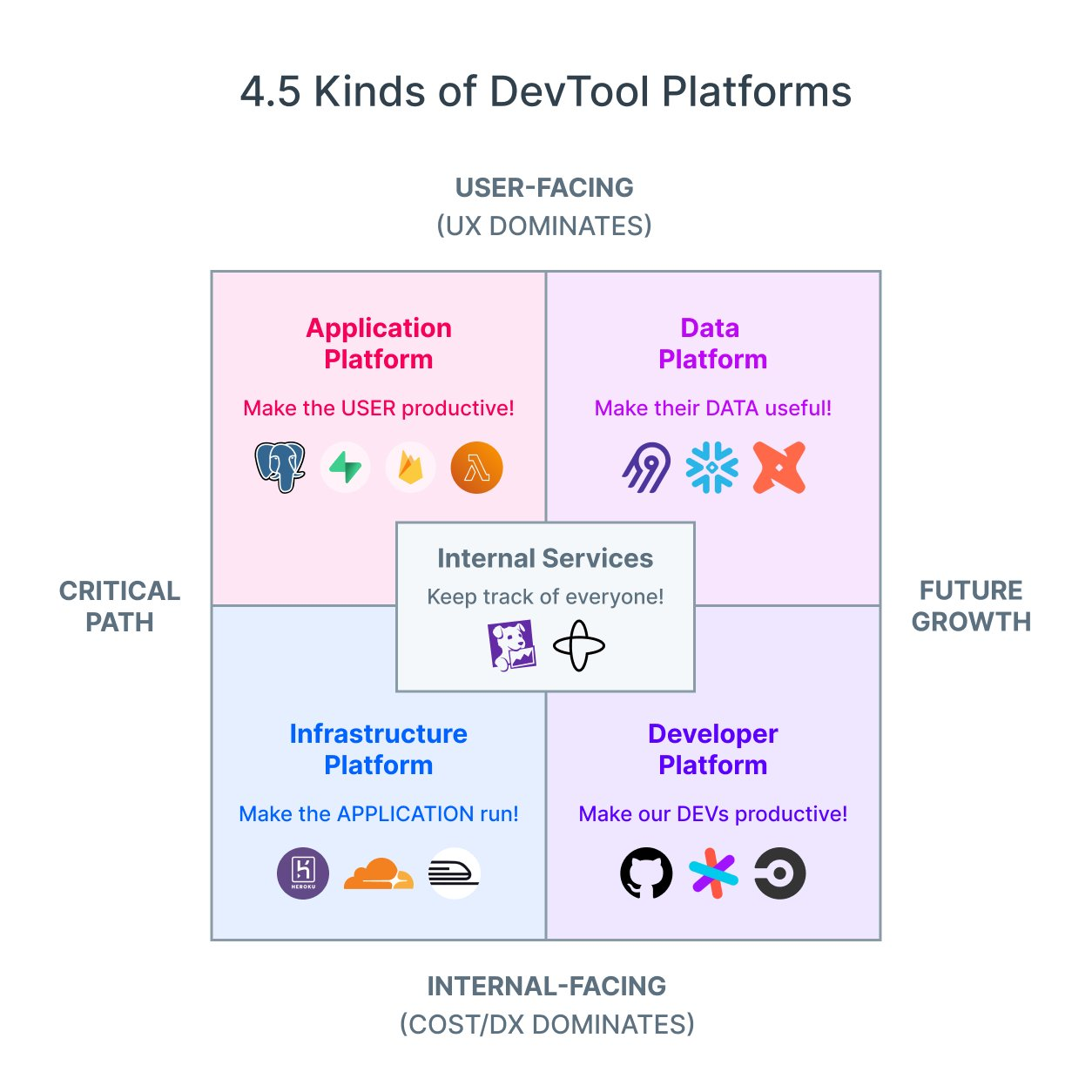
- Application Platform: Make the user productive!
- aka Serving users with business logic
- UI, Compute, External CDN, API Gateway, Message Queues, Authn/Authz, Transactional Database, Search, File Storage, BaaS startups
- Infrastructure Platform: Make the application run!
- Giving the Application all the resources it needs
- Internal Networking, Infra Security, Cloud Infra, DevOps/SRE tooling, PaaS startups
- Data Platform: Make the data useful
- Storing, transforming, enriching, and studying the data coming in from users and integrations
- Data Warehouse, ETL Pipeline, BI/Analytics, Notebooks, Recommendations, Personalization, Metrics/Feature stores, Catalogs, ML
- does Alerting/Notifications belong here? Billing?
- Developer Platform: Make our developers productive!
- Address most of the SDLC
- IDEs, Documentation, CI/CD, Testing, Code Artefacts, Code search, Collaboration tools
- Internal Services: cross-cutting needs to interface with every platform
- Monitoring, Security, Workflow Engine, (what else? Billing? Chaos/DR/BCP?)
- When does this evolve into a control plane? or "platform of platforms"?
I haven't yet done the work to put numbers to all these categories yet, but intuitively it feels more right than anything I've yet come across in fitting all the startups I see. A final question is - what parts of these platforms should be open source, and what are not? You can check out Rajko Radovanović survey of all attempts here.
